
昨今話題のChatGPTとは何か?
当記事では、自身で整理した内容を備忘録として残していきます。
ChatGPTとは
GIZMODO の記事によると、オリジナルのテキストを生成することができる人工知能ツール、とのこと。
ChatGPTは「オリジナルのテキストを生成することができる人工知能ツール」です。対話型のサービスで、質問に答えてもらうことも、クリエイティブなプロンプトを入力すること(「海を背景にしたビジュアルエフェクトの作り方は?」とか)もできますし、詩や歌、エッセイ、短編小説、コードなどを書いてもらうこともできます。
https://www.gizmodo.jp/2023/02/chat-gpt-openai-ai-finance-ai-everything-we-know.html#1
どうやって使うのか?
それで、OpenAIのアカウント登録さえすれば誰でも使えるようです。また、日本語も対応しているようで、日本語で話しかけると、日本語で返答してくれるようです。
こちらのサイトから利用(アカウントの登録含む)できます。https://openai.com/blog/chatgpt/
仕組み
ウィキペディアによれば、OpenAIのGPT-3.5ファミリーの言語モデルを基に構築(転移学習された)されたとのこと。
OpenAIのGPT-3.5ファミリーの言語モデルを基に構築されており、教師あり学習と強化学習の両方の手法で転移学習されている[2]。
https://ja.wikipedia.org/wiki/ChatGPT
GPT-3.5とは?
そもそも、GPT-3.5ですが、texal の記事によれば、大規模言語モデルGPT-3ファミリーの新モデルとのことです。
OpenAIは、AIを搭載した大規模言語モデルGPT-3ファミリーの新モデル、text-davinci-003を発表した。“GPT-3.5”とでも呼べるこのモデルは、前モデルよりも複雑な命令を処理し、より高品質で長い形式のコンテンツを生成することで改良されていると報じられている。
https://texal.jp/2022/12/01/openai-releases-gpt-3-5-and-chatgpt-an-interactive-ai-model-for-admitting-mistakes/
大規模言語モデルとは?
THE BRIDGE の記事によれば、非常に大きなテキストベースのデータセット(コーパス)を用いることで、教師学習無しで扱えるようです。
大規模言語モデルは非常に大きなテキストベースのデータセットを用いて、ほとんどあるいは全く教師学習なしで、言語の認識、要約、翻訳、予測、生成を行うことができる学習アルゴリズムである。顧客の質問に答えたり、テキスト、音声、画像を高い精度で認識・生成するなど、多様なタスクを処理することができ、テキストから画像への変換以外にも、テキストからテキスト、テキストから3D、テキストからビデオ、デジタル生物学など、さまざまなモダリティが増え続けている。
https://thebridge.jp/2022/12/large-language-models-broaden-ais-reach-in-industry-and-enterprises-1#:~:text=%E5%A4%A7%E8%A6%8F%E6%A8%A1%E8%A8%80%E8%AA%9E%E3%83%A2%E3%83%87%E3%83%AB%E3%81%AF,%E3%81%A7%E3%81%8D%E3%82%8B%E5%AD%A6%E7%BF%92%E3%82%A2%E3%83%AB%E3%82%B4%E3%83%AA%E3%82%BA%E3%83%A0%E3%81%A7%E3%81%82%E3%82%8B%E3%80%82
また、大規模言語モデルは、畳み込みやリカレントモデルを置き換える位置づけのようです。
実際、大規模言語モデルは最も新しく最も強力なモデルの1つであり、畳み込み(convolutional)やリカレント(recurrent)といったモデルに取って代わりつつある。
https://thebridge.jp/2022/12/large-language-models-broaden-ais-reach-in-industry-and-enterprises-1#:~:text=%E5%A4%A7%E8%A6%8F%E6%A8%A1%E8%A8%80%E8%AA%9E%E3%83%A2%E3%83%87%E3%83%AB%E3%81%AF,%E3%81%A7%E3%81%8D%E3%82%8B%E5%AD%A6%E7%BF%92%E3%82%A2%E3%83%AB%E3%82%B4%E3%83%AA%E3%82%BA%E3%83%A0%E3%81%A7%E3%81%82%E3%82%8B%E3%80%82
ちなみに、転移学習って、どのようにするの?
と疑問に思われた方は、こちらの記事が参考になるかと思います。
まず第一段では、ImageNetなどのコンテスト向けに作成されたディープラーニングのモデル(及び学習済みの重み含む)を、最終層(フル結合層:FC。ImageNetでは1000クラスに分類)以外の部分を利用して、入力画像を特徴量に変換します。この変換後の特徴量を、ボトルネック特徴量とも言います。
次に第二段では、新規に作成した任意のアウトプットを出力する簡単なモデル(今回は2クラスに分類する)に対して、上記のボトルネック特徴量を入力として学習、予測を行います。
ここで重要なのは、「第一段で利用した利用元のモデルでは一切学習を行なっていない」という点です。
https://qiita.com/yampy/items/6f1f48fee16db7888f07
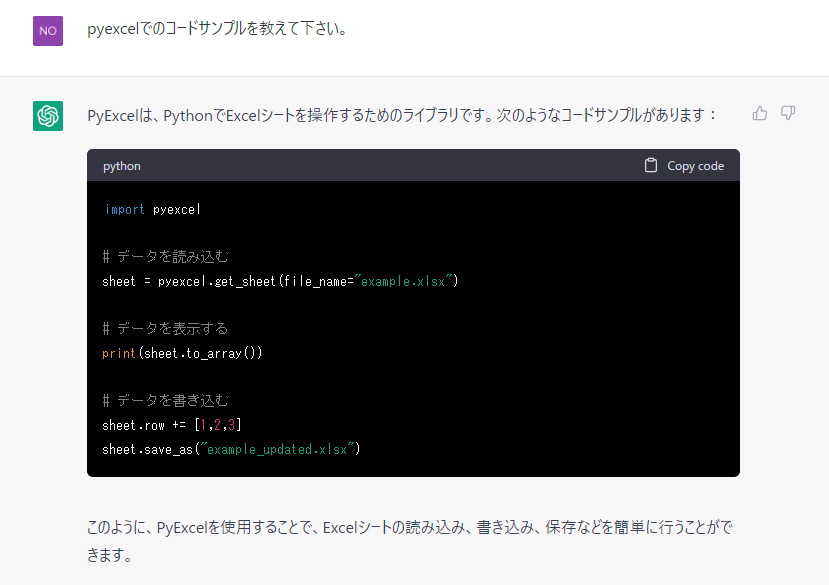
実際につかってみました。例では、pyexcel を用いたコーディング例について尋ねてみましたが、これ、結構使えそうですね。検索エンジンよりも、使えそうです。
ChatGPTをはじめるときに最初に読む本: 小学生でもやり方がわかるChatGPTの本
新品価格
¥99から
(2023/2/9 10:47時点)
ChatGPTの入門書: 初心者向けの解説と利活用方法を紹介
新品価格
¥350から
(2023/2/9 10:52時点)
ゼロから始めるChatGPT: 基礎から応用まで (AIライブラリ by 相武AI)
新品価格
¥980から
(2023/2/9 10:52時点)
